– Appropriating Existing Technologies:
I used p5speech library to get speech to text and send data to socketOSC to maxMSP to created sounds. My first idea is using STT to compose hip-hop-jazz song. I started with google what is the most used hip-hop word. the results are
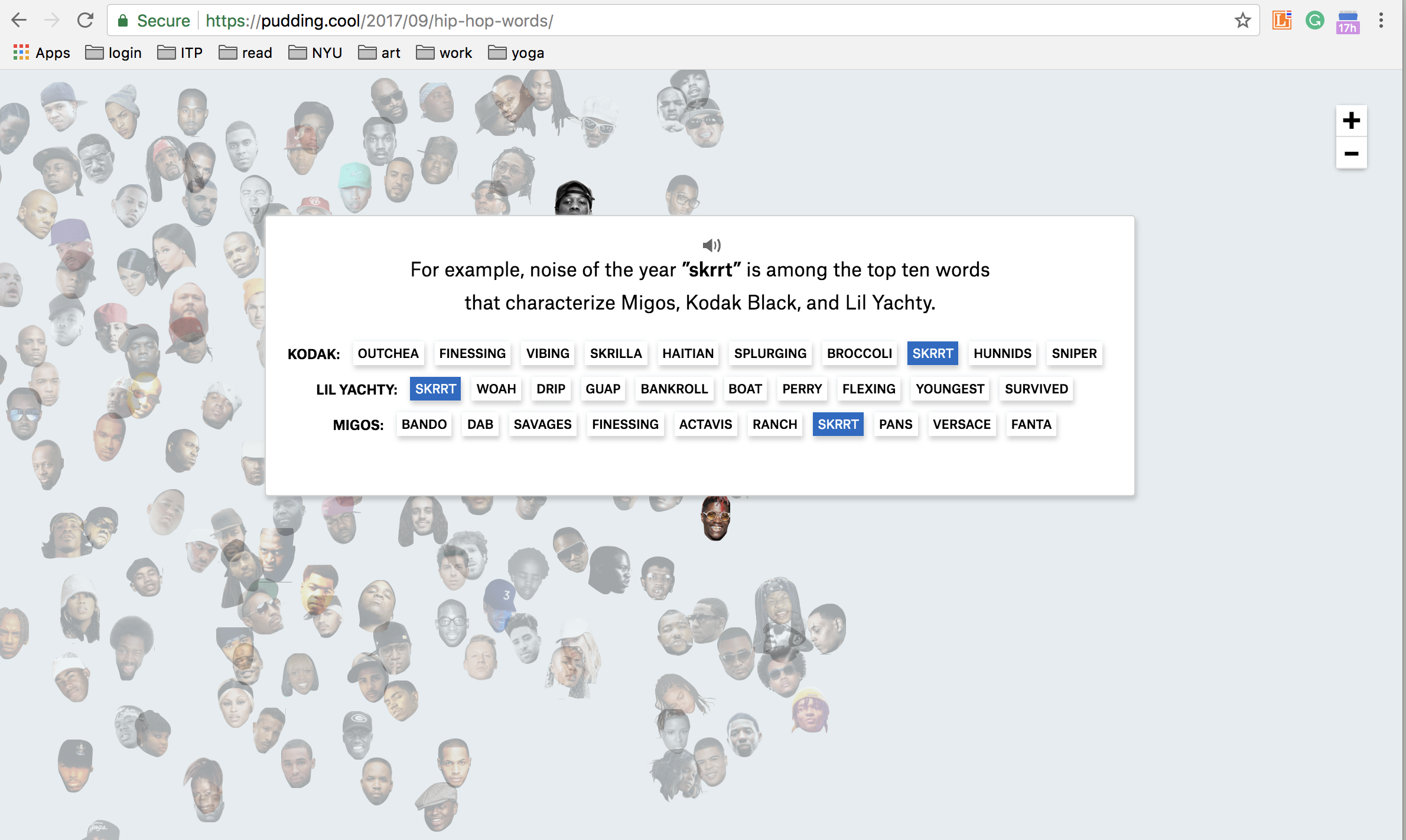

Sadly, the p5speech cannot get non of these slangs. or my accent is bad. So I tried more simple words.
“hey” “okay” “well” “no”
When the p5speech get one of these words, It will activate my sample sound. When I said the same word again, It will deactivate the sound. The interesting part is, p5speech didn’t know if it was one word or a sentence. For example, When I said “no” “no” to close. It will get “no no” string. which is my Max patch don’t understand if it sends like that. I was interested to play with the time of waiting and those things created rhythm.
Here is some testing